

<*href: Cory Arcangel: on Compression, 2007>
A Discrete Cosine Transform or 64 basis functions of the JPEG compression (Joint Photographic Experts Group) 8 x 8 pixel macroblocks.
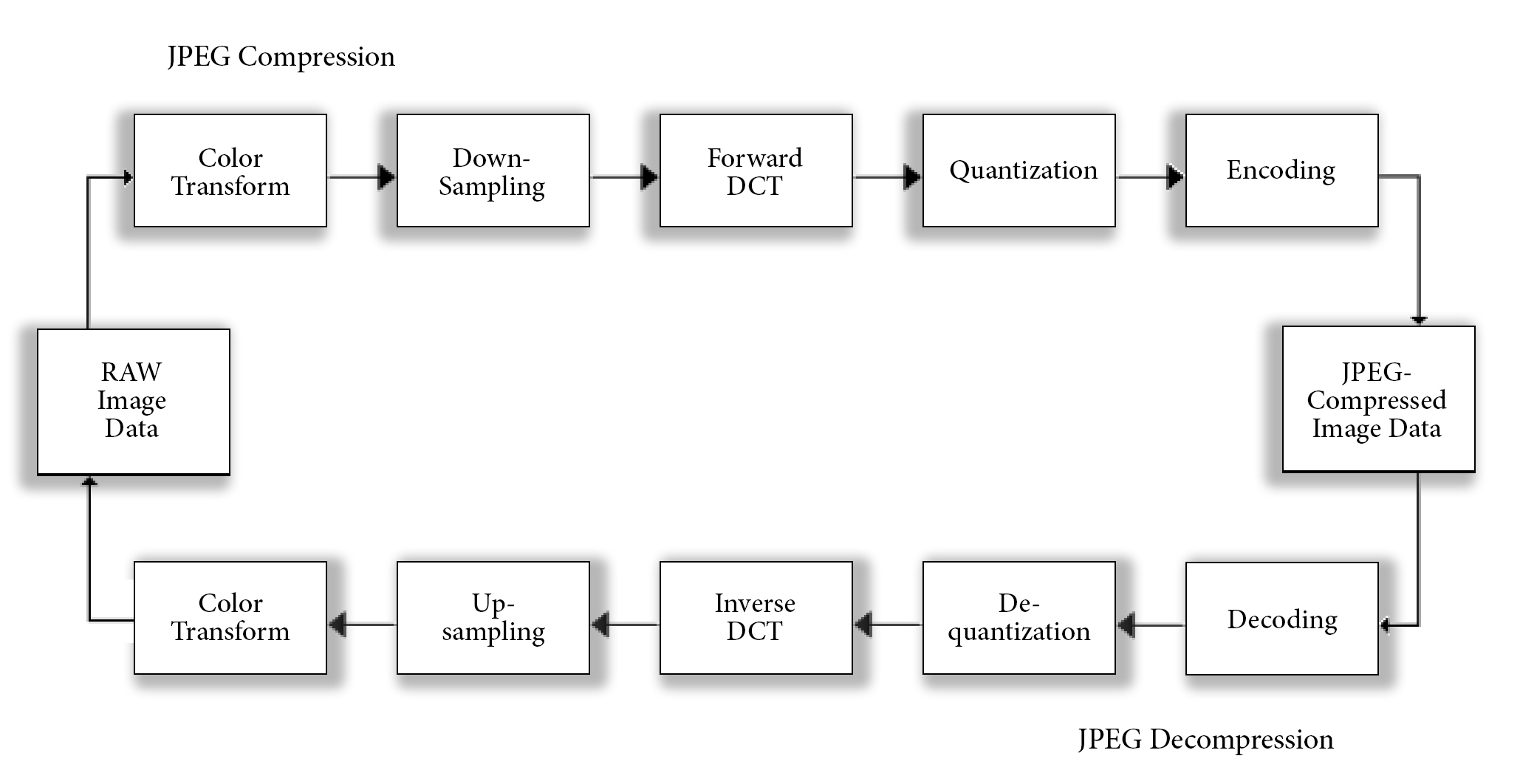 The .JPEG compression consists of these six subsequent steps
The .JPEG compression consists of these six subsequent steps
1. Color space transformation. Initially, the image has to be transformed from the RGB colorspace to
Y′CbCr. This colorspace consists of three components that are handled separately; the Y’ (luma or brightness) and the Cb and Cr values; the blue-difference and red-difference Chroma components.
2. Downsampling. Because the human eye doesn’t perceive small differences within the Cb and Cr space very well, these elements are downsampled, a process that reduces its data dramatically.
3. Block splitting. After the colorspace transformation and downsampling steps, the image is split into 8 x 8 pixel tiles or macroblocks, which are transformed and encoded separately.
4. Discrete Cosine Transform. Every Y’CbCr macroblock is compared to all 64 basis functions (base cosines) of a Discreet Cosine Transform. A value of resemblance per macroblock per base function is saved in a matrix, which goes through a process of reordering.
5. Quantization. The JPEG compression employs quantization, a process that discards coefficients with values that are deemed irrelevant (or too detailed) visual information. The process of quantization is optimized for the human eye, tried and tested on the Caucasian Lena color test card.
Effectively, during the quantization step, the JPEG compression discards most of all information within areas of high frequency changes in color (chrominance) and light (luminance), also known as high contrast areas, while it flattens areas with low frequency (low contrasts) to average values, by re-encoding and deleting these parts of the image data. This is how the rendered image stays visually similar to the original – least to human perception. But while the resulting image may look similar to the original, the JPEG image compression is Lossy, which means that the original image can never be reconstructed.
6. Entropy coding. Finally, a special form of lossless compression arranges the macroblocks in a zigzag order. A Run-Length Encoding (RLE) algorithm groups similar frequencies together while Huffman coding organizes what is left.
 Revealing the surface and structure of the image *
Revealing the surface and structure of the image *<href: Ted Davis: ffd8, 2012>
A side effect of the JPEG compression is that the limits of the images’ resolution – which involve not just the images’ number of pixels in length and width, but also the luma and chroma values, stored in the form of 8 x 8 pixel macroblocks – are visible as artifacts when zooming in beyond the resolution of the JPEG.
Because the RGB color values of JPEG images are transcoded into Y’CbCr macroblocks, accidental or random data replacements can result into dramatic discoloration or image displacement. Several types of artifacts can appear; for instance ringing, ghosting, blocking, and staircase artifacts. The relative size of these artifacts demonstrates the limitations of the JPEGs informed data: a highly compressed JPEG will show relatively larger, block-sized artifacts.

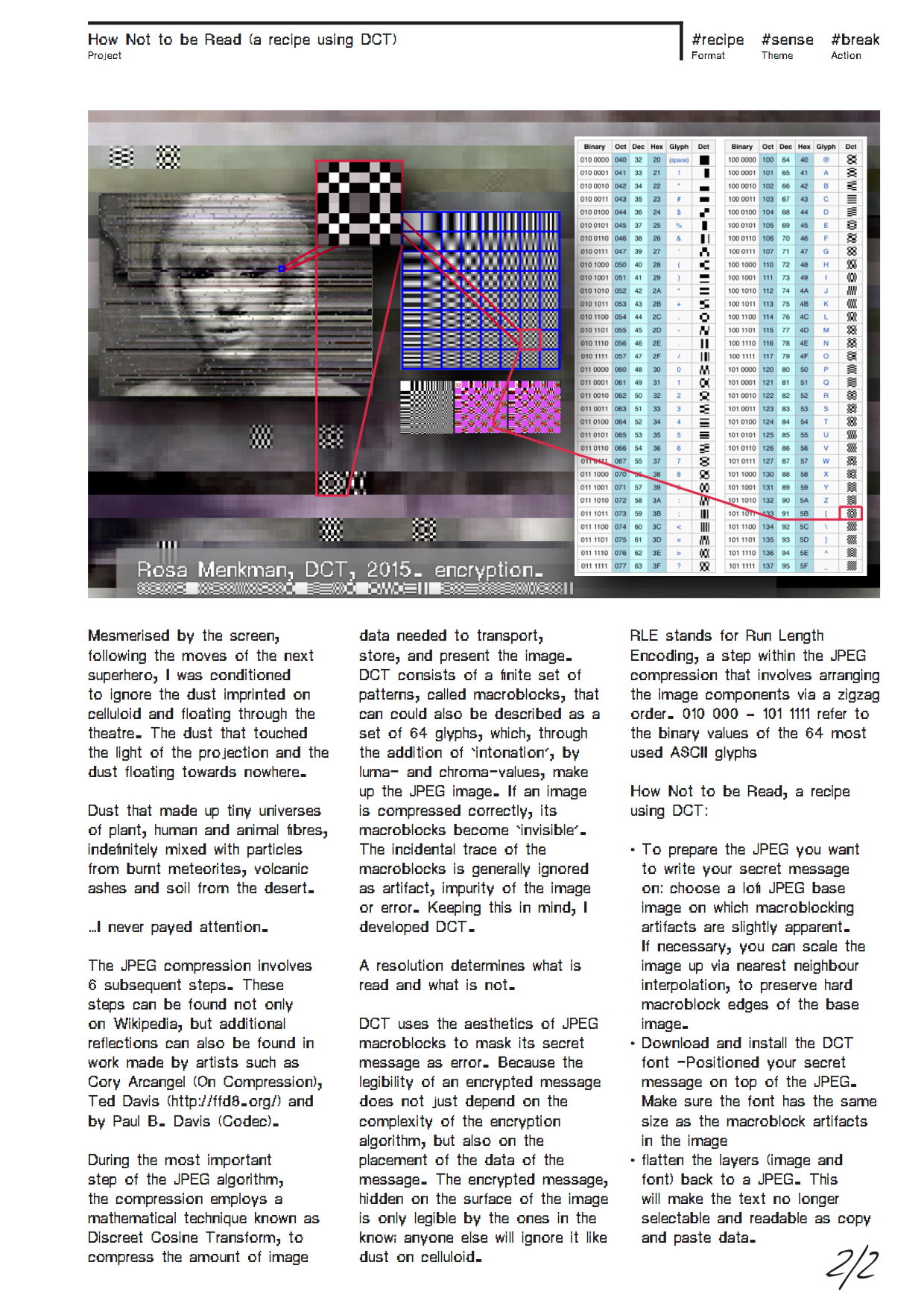
HOW NOT TO BE READ* [ a recipe using DCT ENCRYPTION ]
<href: Hito Steyerl: How Not to Be Seen, 2013>
The legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the data of the message. Here they are closely connected to resolutions: resolutions determine what is read and what is unseen or illegible.
DCT ENCRYPTION (2015) uses the aesthetics of JPEG macroblocks to mask its secret messages on the surface of the image, mimicking error. The encrypted message, hidden on the surface is only legible by the ones in the know; anyone else will ignore it like dust on celluloid.
While the JPEG compession consists of 6 steps, the basis of the compression is DCT, or Discrete Cosine Transform. During the final, 6th step of the JPEG compression, entropy coding, a special form of lossless data compression, takes place. Entropy coding involves the arranging the image components in a "zigzag" order, using run-length encoding (RLE) to group similar frequencies together.
How Not to be Read, a recipe using DCT:
︎ for the #3D Additivist Cookbook.
︎ DCT won the Crypto Desgin Challenge Award in 2015.
<href: Hito Steyerl: How Not to Be Seen, 2013>
A PDF with this work is downloadable here
The legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the data of the message. Here they are closely connected to resolutions: resolutions determine what is read and what is unseen or illegible.
DCT ENCRYPTION (2015) uses the aesthetics of JPEG macroblocks to mask its secret messages on the surface of the image, mimicking error. The encrypted message, hidden on the surface is only legible by the ones in the know; anyone else will ignore it like dust on celluloid.
While the JPEG compession consists of 6 steps, the basis of the compression is DCT, or Discrete Cosine Transform. During the final, 6th step of the JPEG compression, entropy coding, a special form of lossless data compression, takes place. Entropy coding involves the arranging the image components in a "zigzag" order, using run-length encoding (RLE) to group similar frequencies together.
How Not to be Read, a recipe using DCT:
- Choose a lofi JPEG base image on which macroblocking artifacts are slightly apparent. This JPEG will serve as the image on which your will write your secret message.
- If necessary, you can scale the image up via nearest neighbour interpolation, to preserve hard macroblock edges of the base image.
- Download and install the DCT font
- Position your secret message on top of the JPEG. Make sure the font has the same size as the macroblock artifacts in the image
- Flatten the layers (image and font) back to a JPEG. This will make the text no longer selectable and readable as copy and paste data.
︎ for the #3D Additivist Cookbook.
︎ DCT won the Crypto Desgin Challenge Award in 2015.

 A Discrete Cosine Transform simplified to make a monochrome .ttf font and iRD logo. In the logo RLE 010 000 - 101 1111 signifies the key to the DCT encryption: 010 000 - 101 1111 are the binary values of the 64 most used ASCII glyphs, which are then mapped onto the DCT in a zig zag order (following RLE).
A Discrete Cosine Transform simplified to make a monochrome .ttf font and iRD logo. In the logo RLE 010 000 - 101 1111 signifies the key to the DCT encryption: 010 000 - 101 1111 are the binary values of the 64 most used ASCII glyphs, which are then mapped onto the DCT in a zig zag order (following RLE).

Discrete Cosine Transform (DCT) was first conceived for the Crypto Design Challenge
“A recipe using DCT” was released in the #Additivism cookbook.
Mesmerized by the screen, focusing on the moves of a next superhero, I was conditioned to ignore the dust imprinted on the celluloid or floating around in the theater, touching the light of the projection and mingling itself with the movie.
The dust – micro-universes of plant, human and animal fibers, particles of burnt meteorites, volcanic ashes, and soil from the desert – could have told me stories reaching beyond my imagination, deeper and more complex than what resolved in front of me, reflecting from the movie screen.
… But I never paid attention.
I focused my attention to where I was conditioned to look: to the feature, reflecting from the screen. All I saw were the images. I did not see the physical qualities of the light nor the materials making up its resolution; before, behind, and beyond the screen.
Decennia of conditioning the user to ignore these visual artifacts and to pay attention only to the overall image has changed these artifacts into the ultimate camouflage for secret messaging. Keeping this in mind, I developed DCT.
☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰
Premise of DCT is the realisation that the legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the message. This encrypted message, hidden on the surface of the image, is only legible by the ones in the know; anyone else will ignore it. Like dust on celluloid, DCT is mimics JPEG error. It appropriates the algorithmic aesthetics of JPEG macroblocks to stenographically mask a secret message, mimicking error. The encrypted message, hidden on the surface of the image, is only legible by the ones in the know.
“A recipe using DCT” was released in the #Additivism cookbook.
Mesmerized by the screen, focusing on the moves of a next superhero, I was conditioned to ignore the dust imprinted on the celluloid or floating around in the theater, touching the light of the projection and mingling itself with the movie.
The dust – micro-universes of plant, human and animal fibers, particles of burnt meteorites, volcanic ashes, and soil from the desert – could have told me stories reaching beyond my imagination, deeper and more complex than what resolved in front of me, reflecting from the movie screen.
… But I never paid attention.
I focused my attention to where I was conditioned to look: to the feature, reflecting from the screen. All I saw were the images. I did not see the physical qualities of the light nor the materials making up its resolution; before, behind, and beyond the screen.
Decennia of conditioning the user to ignore these visual artifacts and to pay attention only to the overall image has changed these artifacts into the ultimate camouflage for secret messaging. Keeping this in mind, I developed DCT.
☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰☰
Premise of DCT is the realisation that the legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the message. This encrypted message, hidden on the surface of the image, is only legible by the ones in the know; anyone else will ignore it. Like dust on celluloid, DCT is mimics JPEG error. It appropriates the algorithmic aesthetics of JPEG macroblocks to stenographically mask a secret message, mimicking error. The encrypted message, hidden on the surface of the image, is only legible by the ones in the know.







Making the Sun write cryptographic shadow messages wit DCT.

DCT at MOTI for the Crypto design challenge
Encrypted text:
The legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the data of the message.
The Discreet Cosine Transform is a mathematical technique. In the case of the JPEG compression, a DCT is used to describe a finite set of patterns, called macroblocks, that could be described as the 64 character making up the JPEG image, adding lumo and chroma values as ‘intonation’.
If an image is compressed correctly, its macroblocks become ‘invisible’. The incidental trace of the macroblocks is generally ignored as artifact or error.
Keeping this in mind, I developed DCT. DCT uses the esthetics of JPEG macroblocks to mask its secret message as error. The encrypted message, hidden on the surface of the image is only legible by the ones in the know.
︎ A PDF about this work is downloadable here
︎ Visit the DCT ENCRYPTION STATION (2022, w/ Ted Davis) here
︎ DCT DECOY with Erik Axel Eggelink.
Encrypted text:
The legibility of an encrypted message does not just depend on the complexity of the encryption algorithm, but also on the placement of the data of the message.
The Discreet Cosine Transform is a mathematical technique. In the case of the JPEG compression, a DCT is used to describe a finite set of patterns, called macroblocks, that could be described as the 64 character making up the JPEG image, adding lumo and chroma values as ‘intonation’.
If an image is compressed correctly, its macroblocks become ‘invisible’. The incidental trace of the macroblocks is generally ignored as artifact or error.
Keeping this in mind, I developed DCT. DCT uses the esthetics of JPEG macroblocks to mask its secret message as error. The encrypted message, hidden on the surface of the image is only legible by the ones in the know.
︎ A PDF about this work is downloadable here
︎ Visit the DCT ENCRYPTION STATION (2022, w/ Ted Davis) here
︎ DCT DECOY with Erik Axel Eggelink.